Addendum
DepthViewer
- 2022.10 - 2024.02
- 사용 언어: C# + Python
- 사용 기술: Unity, ONNX, Pytorch 등
제가 가장 오래 진행했던 프로그램입니다.
동기
2022년 딥러닝이 계속해서 발달하고 있을때, 이미지 프로세싱에 대한 관심이 있었습니다. 특히 2019년에 사고 장롱에서 못나오고 있던 VR 헤드셋을 활용할 수 있었으면 했습니다. VR에서 시청할 수 있는 미디어의 수가 한정되어 있고, 그 미디어도 제가 흥미를 느끼지 못하는 것이 많았습니다. 그래서 해결하고자 하는 문제: “발달한 머신러닝 기술을 이용해 일반적인 이미지를 VR을 위해 가공할 수 있었으면 좋겠다”가 인식되었습니다.
선행사례
현대인의 친구 구글을 통해 탐색해 본 결과 저와 비슷한 생각을 했던 팀이 있었습니다. 이미지를 Monocular Depth Estimation Model을 이용하여 깊이 정보를 infer한 후, 3D 환경에 표시하여 깊이를 더한 것이었습니다. 하지만 그 프로젝트가 closed source이라는 것 하나로 제가 원하는 기능을 추가할 수 없었습니다.
- 모델 변경 불가: 당시 State-of-art 위치에 있었고 지금도 쓸만한 MiDaS 모델이 내장되어 있었지만 오래된 모델이라 효율성이 떨어졌습니다.
- 적용 대상 제한됨: 특정 동영상만 사용 가능하여 확장성이 떨어졌습니다.
- 기능 추가 불가: Closed source라 당연했습니다. 당시 3D 프로그래밍은 이전에 시험삼아 C로 간단한 게임을 만들어 본 것이 전부였지만 제 것을 만들고 싶다는 열정에 바로 프로젝트에 착수했습니다.
시작: depth.py
어릴때부터 C의 간결성에 매료되어 제 주 언어로 사용했지만 (초등학생때 플래시를 위해 익힌 ActionScript 제외) 점차 Python의 간편함에 익숙해져왔습니다. 특히 pseudo-code스러운 문법때문에 어떤 프로젝트던지 간단한 파이썬 스크립트로 시작하는 것이 많았습니다. 이 프로젝트도 마찬가지였는데, 지금은 몇천줄이 넘어가지만 처음에는 몇줄의 파이썬 스크립트로 시작했습니다.
대상 이미지 준비
먼저 이미지나 동영상을 ML모델이 사용할 수 있도록 가공해야 했습니다. 이때 이전에 다른 프로젝트 (이것도 3D와 관련되었음)을 통해 익힌 OpenCV 라이브러리가 큰 도움이 되었습니다.
ML 모델을 통한 Monocular Depth Estimation
Github을 뒤지던 중 MiDaS 모델이 가장 좋아보였습니다. (이것이 위의 closed source 프로그램이 사용한 것과 같다는 것은 나중에 알게되었습니다.)
특히 소형 모델인 v2.1 small은 용량과 요구사양이 낮아 쉽게 내장할 수 있었습니다.
Infer을 위한 Pytorch 코드는 이전에 Müller & Guido와 Géron의 입문서들로 익힌 기본지식으로 작성할 수 있었습니다.
처리된 Depth map 저장
프레임 당 Depth map을 간단한 이미지 형식인 PGM으로 변환하여 ZIP파일에 저장하여 나중에 사용할 수 있도록 하였습니다.
시각화…?
이 Depth map 파일 (편의상 Depthfile로 불렀습니다)을 어떻게 시각화할지는 정해지지 않았습니다. Matplotlib과 같은 파이썬 라이브러리를 사용할 지, Javascipt 위에서 돌아가는 웹 라이브러리를 사용할 지, 이전에 간단하게 배운 Qt 프레임워크를 사용할 지, 전에 C로 배운 Raylib 3D 엔진을 사용할 지 고민하다가 결국 널리 쓰였던 게임 엔진인 Unity를 선택하게 되었습니다.
Unity / C#?
물론 저는 게임 엔진은 Scratch말고는 경험이 없었기에, 입문서를 하나 구해 공부했습니다. 다행히 C#은 꽤 직관적인 언어였습니다.
개발 시작…
책을 어느정도 끝내고 난 뒤 개발을 시작했습니다. 텍스쳐와 Depth map을 하드코딩한 후 mesh를 생성하고, depth map을 읽어 vertex들의 위치를 조정하여 렌더링하면 되었습니다. VR HMD 지원은 Unity 위에서 간단히 구현가능했습니다.
Mesh visualization
처음에 vertex들을 조정해서 렌더링했을때 작동했지만 무언가 뒤틀림을 느꼈습니다.
알고보니 MiDaS는 relative inverse depth를 계산하기 때문에 역수를 취해야 했습니다.
따라서 파라미터 Alpha, Beta를 이용하여 inverse하였습니다.
그 후 Alpha, Beta의 값에 따라 최소/최대값이 정해짐을 보고 normalize했습니다.
for (int i = 0; i < _depth.Value.Length; i++) { //_alpha and _beta are assured to be positive
float z = _depth.Value[i];
if (_depth.Type == DepthMapType.Inverse) {
/*
`_depths` are normalized to [0, ..., 1]
MiDaS returns inverse depth, so let k be
1 / (a*x + b)
where a > 0, b > 0.
Now k's are [1/b, ... , 1/(a+b)]
Normalize such that z be
(k * (a + b) - 1) * b / a
This gives us [1, ..., 0], where 0 is the closest.
*/
/*
If the Threshold [0, ..., 1] is set (that is, nonzero), set all values below it as the TargetVal.
*/
z = (1 / (_alpha * z + _beta)); //inverse
z = (z * (_alpha + _beta) - 1) * _beta / _alpha; //normalize
}
_vertices[i].z = z * _depthLength * _depthMultR;
Mesh projection
위 inversion은 model의 출력에서 expected된 것이지만 또다른 문제가 발생했습니다. VR 카메라가 orthographic projection이 아니라 perspective projection이기 때문에 뒤에 있는 vertex들이 너무 작아져 3D 효과가 낮아졌습니다. 이에 뒤에 있는 vertex들을 “펴서” 이를 완화해야 했습니다.
그래서 perspective projection이지만, 뒤에 있는 vertex들을 카메라로 볼때 원래 위치로 옮겨 3D 정보가 없다면 마치 2D처럼 보이게 해야했습니다.
이에 새 파라미터 ProjRatio를 넣어 1일 때 full projection, 0일 때 projection 없음으로 하였습니다.
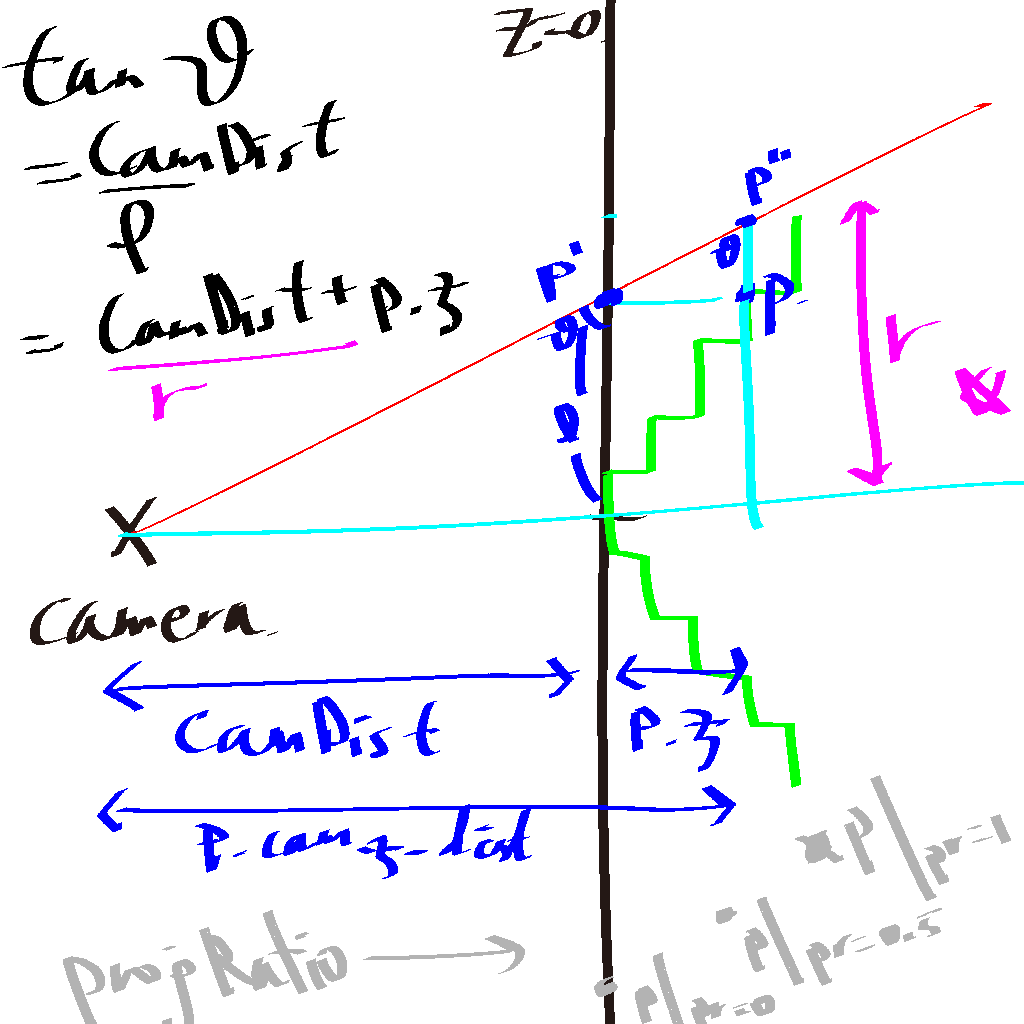
if (_projRatio == 0)
continue; //Continue without projecting
/*
Project vertices on camera
For vertex p, we want the distance between p and z-axis (i.e. how far will p be from the center on camera) to be linearly related to the distance between p and the camera.
The difference between p.z and Camera.z is
p.cam_z_dist := CamDist + p.z
Let's fix the location of vertices whose z are 0.
Let p' be the projection of p on plane z = CamDist (i.e. z_p = 0)
Since p.x = p'.x and p.y = p'.y,
tan (theta_p') = sqrt(p.x^2 + p.y^2) / CamDist
Using the same angle, if we let p" be the projection of p' on the original xy-plane of p,
tan (theta_p') = tan (theta_p") = p".r / p.cam_z_dist
=> p".r = tan (theta_p') * p.cam_z_dist
p".r being the distance between p" and z-axis.
Thus the (x, y) of p" can be calculated from (p.x, p.y).normalized * p".r
*/
/*
Use parameter ProjRatio [0, 1] to set the magnitude
*/
Vector3 p = _vertices[i];
float prop = (p.z * scale * _projRatio + CamDist) / (CamDist); //multiply p.z by scale to get the absolute value
float orig_rad = MathF.Sqrt(p.x*p.x + p.y*p.y);
if (orig_rad == 0) orig_rad = 0.00001f; //Avoid divide-by-zero
float new_rad = prop * orig_rad;
Vector2 newXY = new Vector2(p.x, p.y) / orig_rad * new_rad;
targetVertices[i] = new Vector3(newXY.x, newXY.y, p.z);
}
제가 인용된 부분도 이 부분으로 보입니다.
Unity 내부에서 Infer는?
파이썬에서 만들어진 Depth map ZIP 파일을 읽는 것은 구현되었지만 꽤나 불편한 방식이었습니다. 그래서 Unity 프로그램 내부에서 ML 모델을 이용하는 기능이 필요했습니다. (Unity상에서 셸을 불러 파이썬 스크립트를 실행시키는 기능도 있었지만 그다지 편하진 않았습니다.)
찾아보니 Unity에서 개발한 ML 프레임워크 Barracuda가 있어 MiDaS 모델을 사용할 수 있었습니다.
Barracuda의 한계 봉착
내장했던 MiDaS v2.1 small은 Barracuda와 호환이 잘 되었지만 더 좋은 성능을 보여주었던 (특히 dpt-hybrid 모델이 robust하여 자주 사용하였습니다.) v3+ 모델들은 호환이 안되었습니다.
- Barracuda는 ONNX 모델을 필요로 했는데,
v3모델들은 공식 ONNX 모델이 없었습니다. 다행히 한 유저가 해결책을 제시해주어서 ONNX 모델을 생성할 수 있었습니다. - 그런데 그 ONNX 모델들이 Barracuda와 호환되지 않았습니다.
알고보니 당시 Barracuda의 버전이
v3에서 사용된 명령어를 지원하지 않아 발생한 문제였습니다.
따라서 Barracuda가 아닌 다른 ML 프레임워크를 찾아야 했고, 그 결과 C# 위에서 사용할 수 있는 OnnxRuntime을 사용하게 되었습니다. (C# Pytorch와 같은 라이브러리들은 Unity에서 사용되는 C# 버전과 호환되지 않아 사용하지 못했습니다.)
OnnxRuntime은 속도가 느리고 (특히 Unity에서 지원하는 Barracuda와 달리 이미지 input을 GPU 계산으로 돌리는데 병목이 있었습니다.) CUDA 가속 활성화도 복잡한 과정을 겪어야 했지만 (적지 않은 문의가 있었습니다) 나름 역할을 잘 수행했습니다.
동영상 재생의 한계 봉착
이때까지 동영상 재생은 Unity의 기본 동영상 재생기를 사용했지만 원래 이런 유저 멀티미디어 재생을 위해 만들어 진 것이 아니다 보니 한계가 많았습니다. 특히 이미 널리 쓰이고 있던 VP9 코덱이나 WebM 컨테이너를 지원하지 않던 것이 가장 큰 한계였습니다. 그래서 동영상 재생을 Unity/C# 외부로 분리할 수 있다고 생각했습니다.
이번에도 역시 파이썬으로 동영상 재생 스크립트를 작성했는데, FFmpeg을 wrap한 라이브러리를 사용했습니다.
파이썬 스크립트와의 통신?
이제 이 파이썬 스크립트 (ffpymq.py)와 Unity간의 통신을 구현해야 했습니다. 이전에 Inference 분리를 구현할 때 HTTP를 이용했지만, 오버헤드가 너무 많아 효율이 떨어졌습니다. 따라서 동영상같이 throughput이 큰 통신에는 사용할 수 없었습니다.
그러다 UNIX 강의때 배운 메세지큐를 사용하는 것이 좋겠다고 생각했습니다. 운영체제 레벨의 메세지큐는 확장성이 떨어지기 때문에 어떠한 미들웨어를 사용하기로 했습니다. 탐색 결과 ZeroMQ가 가장 적절하다고 판단되었습니다.
프로토콜
JSON 등을 이용할 수도 있지만 오버헤드를 감수할 만큼 복잡한 작업이 아니라고 판단하고 ptype=RES, ptype=REQ으로 시작되는 간단한 텍스트 프로토콜을 만들어 사용했습니다.
그 코드는 위의 ffpymq.py와 Mqcs.cs에서 확인할 수 있습니다.
예시:
- 요청코드
ptype=REQ
pname=IMAGE_AND_DEPTH
!HEADEREND
- 응답코드 (
<input>과<depth>는 binary string)
ptype=RES
pname=INPUT_AND_DEPTH
status=new
len_input=1234
len_depth=4567
!HEADEREND
<input><depth>
Inference의 분리
입력이 파이썬 스크립트로 분리가 되니 ML 모델 inference도 분리가 되지 않을 이유가 없었습니다. 따라서 위 예시 프로토콜과 같이 파이썬에서 이미지와 함께 그 depth map을 같이 전달함으로써 C#/Unity의 한계도 극복하고 오버헤드도 줄어들었습니다. 또한 ONNX를 사용하지 않는 모델들도 사용할 수 있게 되었습니다.
그 후: Unity ML 프레임워크 업데이트
Barracuda의 연장이라고 할 수 있는 Sentis가 MiDaS v3+ 모델들을 지원하여서 파이썬 스크립트를 더이상 요구하지는 않았지만, 코덱 관련 문제는 잔존해 파이썬 스크립트도 계속 쓰였습니다.
후기
이정도 규모의 프로젝트는 처음 해보는 데다 분야도 제게 새로워서 많은 시행착오를 겪었습니다. 특히 계획을 길게 세우지 않고 생각나는대로, 내지는 요청대로 기능을 추가하다 보니 코드베이스가 조금 난해해지기는 했습니다. 그래도 목표를 달성했고 새 길을 개척한 것 같아 뿌듯했습니다.
GlossySnake
- 2024.03 -
- 사용 기술: ChatGPT API, Django
- 사용 언어: Python
동기
저는 이전부터 언어 및 언어학에 대한 관심이 많았고, 영어를 베이스로 불어, 독어, 라틴어 등 여러 외국어를 배우려 했습니다. 이때 단순 단어 암기와 문법 공부(“grammar-translation method”)보다는 실제 외국어 텍스트를 읽는 것을 선호했습니다. 특히 LLPSI로 대표되는 Natural Method를 선호했습니다. 특히 LLPSI를 오디오와 함께 제공했던 Legentibus를 유용하게 사용했는데, 이 앱에서 제공했던 다른 말뭉치들 중 일부는 단어 당 영어로 주석을 달아놓은 것이 있었습니다. 찾아보니 이러한 방식을 Interlinear gloss라고 하고, 특히 언어학습에 쓰일때는 Hamiltonian system이라고 한다는 것을 알게되었습니다. 이는 19세기 초에 James Hamilton이 개발하여 널리 퍼졌으며 John Stuart Mill도 독일어를 이 방식으로 배웠다고 합니다.
이 방식은 지루한 암기 없이 바로 텍스트를 읽으며 언어를 터득하기 때문에 제가 선호하였지만, 그 특성상 가용한 말뭉치들이 제한되어있어 최근 발달한 자연어 처리를 사용할 수 있다고 생각했습니다. 특히 문장을 통번역하는 기계번역과 달리 언어학습에 더 도움이 되고 기계번역 특성상의 어색함도 무시가능할 수 있다고 판단했습니다.
제작…중
가장 큰 목표를 쉬운 사용성으로 두고 Django로 백엔드를, ChatGPT API를 자연어처리에 사용했는데, 솔직히 말해서 걸린 시간에 비해 구현내용이 더디긴 합니다. 그래도 저를 포함한 언어학습자들이 유용하게 사용할 수 있다고 보고 계속 개발하고 있습니다. 특히 파인튜닝된 ChatGPT API가 아닌 local에서 다른 방법으로 자연어 처리를 하여 gloss를 생성하는 방안과 gloss를 넘어 더 많은 도움을 줄 수 있는 서비스를 개발하는 것을 목표로 하고 있습니다.